Προώθηση της έρευνας στην Τεχνητή Νοημοσύνη για τις διαλέκτους της Νέας Ελληνικής και άλλες γλωσσικές ποικιλίες που ομιλούνται στην Ελλάδα
O χώρος αυτός παρέχει συγκεντρωτική πληροφορία για τους πόρους και τα μοντέλα που αναπτύσσει το Ε.Κ. ΑΘΗΝΑ για την επεξεργασία και τεκμηρίωση διαλέκτων της Νέας Ελληνικής Γλώσσας και άλλων μη ελληνικών γλωσσικών ποικιλιών του ελλαδικού χώρου.
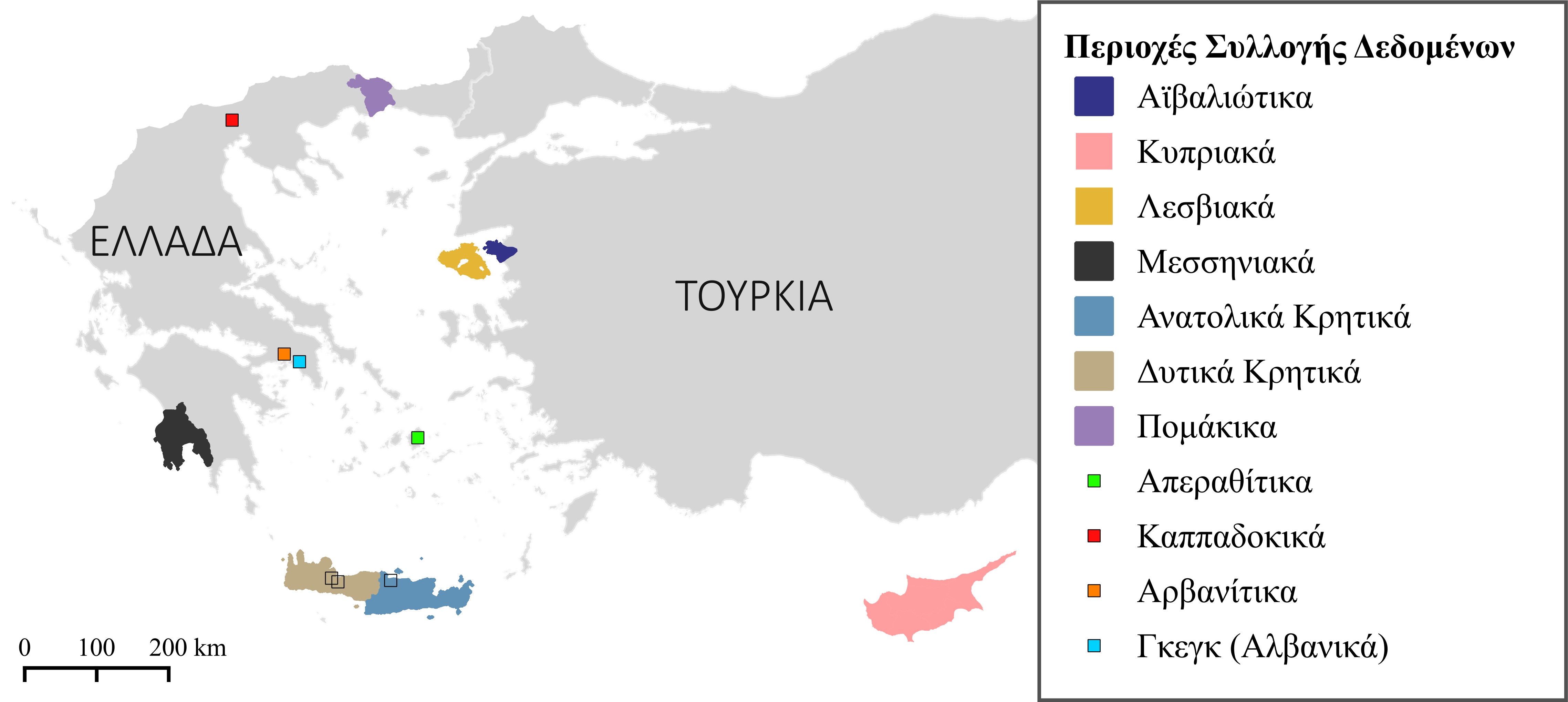
Διάλεκτοι της Νέας Ελληνικής: Η Ελληνιστική Κοινή έχει κληροδοτήσει ένα πλούσιο σύστημα διαλεκτικών ποικιλιών. Κάθε διάλεκτος φέρει ιδιαίτερα γλωσσικά χαρακτηριστικά, μακρά ιστορία και ανεκτίμητη πολιτισμική αξία. Πλέον, οι περισσότερες από αυτές τις διαλέκτους ομιλούνται μόνον στην ελληνική επικράτεια, πολλές όμως κατάγονται από ελληνόφωνες περιοχές εκτός των ορίων του σημερινού ελληνικού κράτους. Η μοναδικότητα των ελληνικών διαλέκτων σε συνδυασμό με την έλλειψη διαλεκτικών δεδομένων αποτελούν ενδιαφέρουσα πρόκληση για την Τεχνητή Νοημοσύνη και τη Γλωσσική Τεχνολογία.
Μη ελληνικές γλωσσικές ποικιλίες του ελλαδικού χώρου: Το Ε.Κ. ΑΘΗΝΑ μελετά και αναπτύσσει πόρους και για γλωσσικές ποικιλίες που ομιλούνται μέσα στην ελληνική επικράτεια αλλά δεν ανήκουν στην ελληνική γλωσσική οικογένεια, όπως τα Πομάκικα (σλαβική γλωσσική οικογένεια), τα Αρβανίτικα και τα Αλβανικά Γκεγκ (αλβανική γλωσσική οικογένεια).
Στο Ε.Κ. ΑΘΗΝΑ, συγκεκριμένα στο Ινστιτούτο Επεξεργασίας του Λόγου (ΙΕΛ) και στην ερευνητική μονάδα ΑΡΧΙΜΗΔΗΣ, αναπτύσσουμε για αυτές τις γλωσσικές ποικιλίες μεθόδους και εργαλεία Τεχνητής Νοημοσύνης και Επεξεργασίας Φυσικής Γλώσσας, ως εξής:
- Συγκεντρώνουμε αυθεντικό προφορικό διαλεκτικό λόγο, κυρίως με έρευνα πεδίου.
- Αναπτύσσουμε μοντέλα μετατροπής ομιλίας σε κείμενο (automatic speech recognition, ASR models).
- Κανονικοποιούμε τις μεταγραφές του προφορικού υλικού με σεβασμό προς την γραπτή παράδοση και τα χαρακτηριστικά των γλωσσικών ποικιλιών.
- Αξιοποιούμε υφιστάμενα διαλεκτικά κείμενα και τις μεταγραφές των προφορικών δεδομένων για την ανάπτυξη δενδροτραπεζών με λεπτομερή μορφοσυντακτική και μορφοφωνολογική επισημείωση.
- Χρησιμοποιούμε τις δενδροτράπεζες για να εκπαιδεύσουμε νευρωνικά μοντέλα μορφοσυντακτικής ανάλυσης της ίδιας ή παρόμοιας γλωσσικής ποικιλίας.
Τα αποτελέσματα της έρευνας περιλαμβάνουν (προφορικά) σώματα κειμένων, μοντέλα μετατροπής ομιλίας σε κείμενο και μοντέλα μορφοσυντακτικής ανάλυσης, δεντροτράπεζες και προδιαγραφές μορφοσυντακτικής επισημείωσης, όλα διαθέσιμα με ανοικτή πρόσβαση.
Ειδικά όσον αφορά τις δενδροτράπεζες, η επισημείωση ακολουθεί το πρότυπο των Universal Dependencies (UD). Οι δενδροτράπεζες μπορούν να ανακτηθούν από τον παρόντα χώρο που παραπέμπει στο αποθετήριο των UD, όπου βρίσκονται και οι μορφοσυντακτικές προδιαγραφές κάθε δενδροτράπεζας. Για κάθε δενδροτράπεζα, δίνουμε το όνομά της, τον σύνδεσμο για το αποθετήριο των UD και την προτιμώμενη μορφή αναφοράς. Ειδικά για την δενδροτράπεζα GUD της Κοινής Νεοελληνικής δίνονται ορισμένοι συνοδευτικοί πόροι: λίστες παγιωμένων πολυλεκτικών λειτουργικών εκφράσεων και scripts για την ταυτοποίηση και ανακάλυψη πολυλεκτικών εκφράσεων με χρήση νευρωνικών μοντέλων.
Παράλληλα, χρησιμοποιούμε Μεγάλα Γλωσσικά Μοντέλα (Large Language Models, LLMs) για να διερευνήσουμε την ανάπτυξη συνθετικών δεδομένων και τη συγκριτική μελέτη των γλωσσικών ποικιλιών με στόχο την ενίσχυση της παρουσίας τους στον χώρο της Τεχνητής Νοημοσύνης.
Στην έρευνα που περιγράφουμε έχουν συμβάλει οι:
- Αντώνης Αναστασόπουλος, Επίκουρος Καθηγητής, George Mason University & ΑΡΧΙΜΗΔΗΣ/Ε.Κ. ΑΘΗΝΑ
- Στέλλα Μαρκαντωνάτου, Διευθύντρια Ερευνών, ΙΕΛ/Ε.Κ. ΑΘΗΝΑ & ΑΡΧΙΜΗΔΗΣ/Ε.Κ. ΑΘΗΝΑ
- Αγγελική Ράλλη, Ομότιμη Καθηγήτρια Γλωσσολογίας, Πανεπιστήμιο Πατρών & ΑΡΧΙΜΗΔΗΣ/Ε.Κ. ΑΘΗΝΑ
- Γιώργος Παρασκευόπουλος, Ερευνητής Γ’, ΙΕΛ/Ε.Κ. ΑΘΗΝΑ
- Χαρά Τσουκαλά, Μεταδιδακτορική Ερευνήτρια, ΙΕΛ/Ε.Κ. ΑΘΗΝΑ
- Βίβιαν Στάμου, Μεταδιδακτορική Ερευνήτρια, ΑΡΧΙΜΗΔΗΣ/Ε.Κ. ΑΘΗΝΑ
- Σταύρος Μπόμπολας, Μεταδιδακτορικός Ερευνητής, ΑΡΧΙΜΗΔΗΣ/Ε.Κ. ΑΘΗΝΑ
- Αντώνης Δημάκης, Υποψήφιος Διδάκτορας, ΕΚΠΑ & ΑΡΧΙΜΗΔΗΣ/Ε.Κ. ΑΘΗΝΑ
- Γιάννης Κάζος, Ηλεκτρολόγος Μηχανικός, Προπτυχιακός Φοιτητής, ΕΜΠ & ΑΡΧΙΜΗΔΗΣ/Ε.Κ. ΑΘΗΝΑ
- Φοιτητές του ΔΠΜΣ Γλωσσική Τεχνολογία, το οποίο συνδιοργανώνεται από το ΕΚΠΑ και το Ε.Κ. ΑΘΗΝΑ.
Διαθέσιμοι Πόροι και Μοντέλα
|
|
Προφορικά σώματα κειμένων |
Μοντέλα μετατροπής ομιλίας σε κείμενο | Δενδροτράπεζες |
Νευρωνικά μορφοσυντακτικά μοντέλα |
| Διάλεκτοι της Νέας Ελληνικής |
Aϊβαλιώτικα |
|||
| Καππαδοκικά v1 |
|
|||
| Κρητικά v1 | Κρητικά | Κρητικά | ||
|
|
Κυπριακά |
Κυπριακά |
||
| Λεσβιακά v1 | Λεσβιακά | |||
| Μεσσηνιακά | Μεσσηνιακά | |||
| Κοινή Νοελληνική | ||||
| Μη ελληνικές γλωσσικές ποικιλίες ομιλούμενες στον ελλαδικό χώρο | ||||
| Πομάκικα | Πομάκικα |
Σημεία επαφής:
Στέλλα Μαρκαντωνάτου, marks@athenarc.gr
Βίβιαν Στάμου, vistamou@athenarc.gr
Σταύρος Μπόμπολας, s.bompolas@athenarc.gr
Αναφορές
Vasileios Arampatzakis, Vivian Stamou, Stella Markantonatou, and George Pavlidis. 2025. Exploring Active Learning Approaches in Treebank Development. In George Pavlidis and Stella Sylaiou, editors, Transforming Heritage Research in a Transforming World: 5th CAA-GR Conference 2024, Springer Proceedings in Archaeology and Heritage, pages 417–425. Springer Nature Switzerland, Cham.
Stavros Bompolas, Stella Markantonatou, Angela Ralli, and Antonios Anastasopoulos. 2025. Crossing Dialectal Boundaries: Building a Treebank for the Dialect of Lesbos through Knowledge Transfer from Standard Modern Greek. In Gosse Bomma and Çağrı Çöltekin, editors, Proceedings of the Eighth Workshop on Universal Dependencies (UDW, SyntaxFest 2025), pages 39–51, Ljubljana, Slovenia. Association for Computational Linguistics.
Ritván Jusúf Karahóǧa, Panagiotis G. Krimpas, Vivian Stamou, Vasileios Arampatzakis, Dimitrios Karamatskos, Vasileios Sevetlidis, Nikolaos Constantinides, Nikolaos Kokkas, George Pavlidis, and Stella Markantonatou. 2022. Morphologically annotated corpora of Pomak. In Sarah Moeller, Antonios Anastasopoulos, Antti Arppe, Aditi Chaudhary, Atticus Harrigan, Josh Holden, Jordan Lachler, Alexis Palmer, Shruti Rijhwani, and Lane Schwartz, editors, Proceedings of the Fifth Workshop on the Use of Computational Methods in the Study of Endangered Languages, pages 179–186, Dublin, Ireland. Association for Computational Linguistics.
Nikolaos T. Kokkas, Stella Markantonatou, and Vasileios Arampatzakis. 2025. Exploration and Digitization of the Pomak Linguistic Corpus. In George Pavlidis and Stella Sylaiou, editors, Transforming Heritage Research in a Transforming World: 5th CAA-GR Conference 2024, Springer Proceedings in Archaeology and Heritage, pages 407–415. Springer Nature Switzerland, Cham.
Stella Markantonatou, Stavros Bompolas, Chara Tsoukala, Socrates Vakirtzian, Vivian Stamou, Angela Ralli, and Antonios Anastasopoulos. 2024. Dialect-aware Modelling for Modern Greek. Paper presented at the 10th International Conference on Modern Greek Dialects and Linguistic Theory (10-12 October -Bova, Rochudi Nuovo, Galliciano, Italy).
Stella Markantonatou, Vivian Stamou, Stavros Bompolas, Katerina Anastasopoulou, Irianna Linardaki Vasileiadi, Konstantinos Diamantopoulos, Yannis Kazos, and Antonios Anastasopoulos. 2025. VMWE identification with models trained on GUD (a UDv.2 treebank of Standard Modern Greek). In Atul Kr. Ojha, Voula Giouli, Verginica Barbu Mititelu, Mathieu Constant, Gražina Korvel, A. Seza Doğruöz, and Alexandre Rademaker, editors, Proceedings of the 21st Workshop on Multiword Expressions (MWE 2025), pages 14–20, Albuquerque, New Mexico, U.S.A. Association for Computational Linguistics.
Stella Markantonatou, Nicolaos Th. Constantinides, Vivian Stamou, Vasileios Arampatzakis, Panagiotis G. Krimpas, and George Pavlidis. 2023. Methodological issues regarding the semi-automatic UD treebank creation of under-resourced languages: the case of Pomak. In Loïc Grobol and Francis Tyers, editors, Proceedings of the Sixth Workshop on Universal Dependencies (UDW, GURT/SyntaxFest 2023), pages 27–35, Washington, D.C. Association for Computational Linguistics.
Chara Tsoukala, Stavros Bompolas, Antigoni Margariti, Konstantina Panagiotou, Maria Elisavet Plaiti, Nefeli Tzanakaki, Petros Karatsareas, Angela Ralli, Antonios Anastasopoulos, and Stella Markantonatou. 2026. Extending ASR Evaluation Resources for Modern Greek Dialects. In Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects, Rabat, Morocco. Association for Computational Linguistics.
Chara Tsoukala, Kosmas Kritsis, Ioannis Douros, Athanasios Katsamanis, Nikolaos Kokkas, Vasileios Arampatzakis, Vasileios Sevetlidis, Stella Markantonatou, and George Pavlidis. 2023. ASR pipeline for low-resourced languages: A case study on Pomak. In Oleg Serikov, Ekaterina Voloshina, Anna Postnikova, Elena Klyachko, Ekaterina Vylomova, Tatiana Shavrina, Eric Le Ferrand, Valentin Malykh, Francis Tyers, Timofey Arkhangelskiy, and Vladislav Mikhailov, editors, Proceedings of the Second Workshop on NLP Applications to Field Linguistics, pages 40–45, Dubrovnik, Croatia. Association for Computational Linguistics.
Socrates Vakirtzian, Vivian Stamou, Yannis Kazos, and Stella Markantonatou. 2025. Dialectal treebanks and their relation with the standard variety: The case of East Cretan and Standard Modern Greek. In Richard Johansson and Sara Stymne, editors, Proceedings of the Joint 25th Nordic Conference on Computational Linguistics and 11th Baltic Conference on Human Language Technologies (NoDaLiDa/Baltic-HLT 2025), pages 776–784, Tallinn, Estonia. University of Tartu Library.
Socrates Vakirtzian, Chara Tsoukala, Stavros Bompolas, Katerina Mouzou, Vivian Stamou, Georgios Paraskevopoulos, Antonios Dimakis, Stella Markantonatou, Angela Ralli, and Antonios Anastasopoulos. 2024. Speech Recognition for Greek Dialects: A Challenging Benchmark. In Interspeech 2024, pages 3974–3978. ISCA.
Αναφορές στα Μέσα Ενημέρωσης
Διασώζοντας την ντοπιολαλιά με ΑΙ Eφημερίδα “H Καθημερινή”, 8 Φεβρουαρίου 2026