Advancing AI for Greek dialects and other language varieties spoken in Greece
This space provides consolidated information about the resources and models developed by the ATHENA Research Center for the processing and documentation of the dialects of Modern Greek and the non-Greek linguistic varieties spoken in the Greek territory.
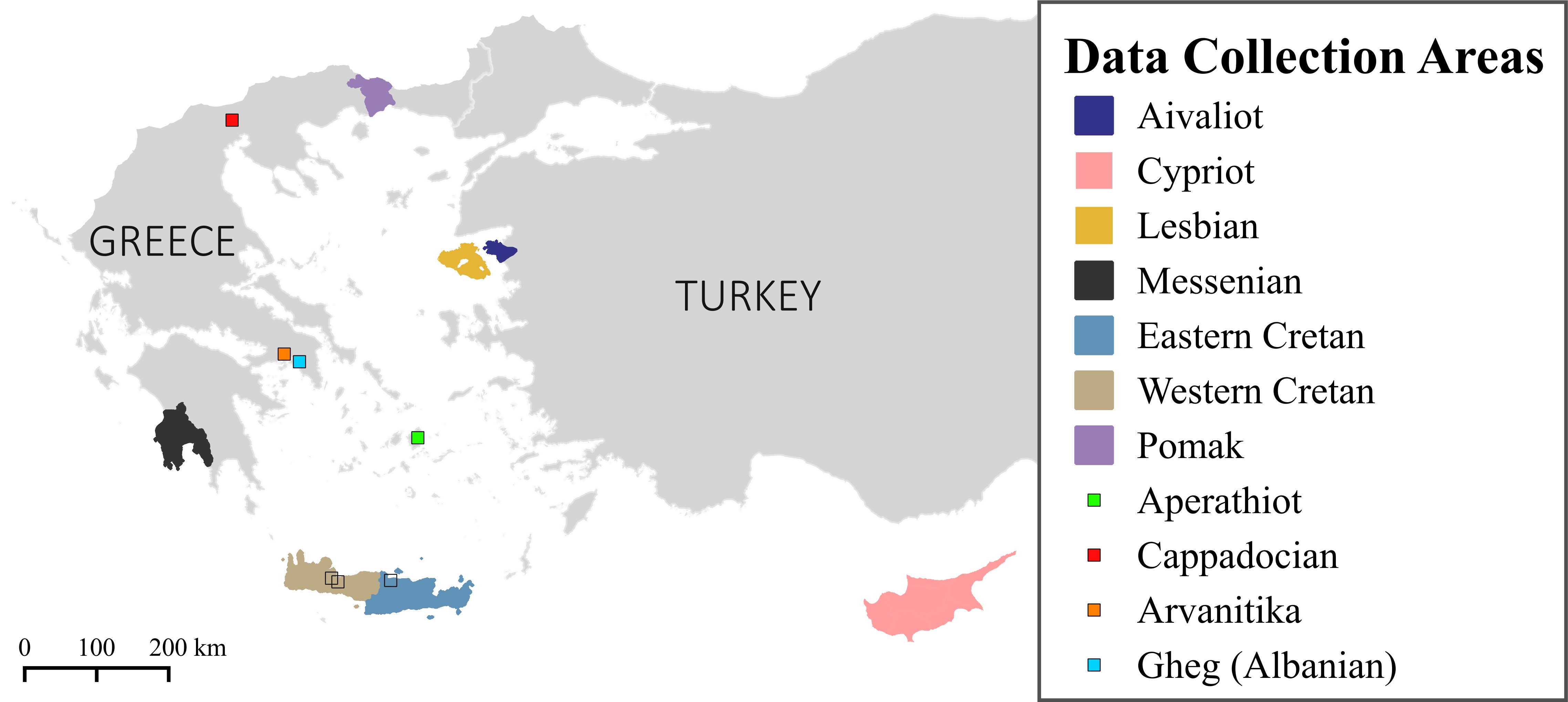
Dialects of Modern Greek:
The Hellenistic Koine has bequeathed a rich system of dialectal varieties. Each dialect carries unique linguistic features, a long history, and invaluable cultural significance. Today, most of these dialects are spoken only within Greece, although many originate from Greek-speaking regions that lie outside the borders of the modern Greek state. The uniqueness of Greek dialects, combined with the scarcity of dialectal data, presents an intriguing challenge for Artificial Intelligence and Language Technology.
Non-Greek linguistic varieties in Greece:
ATHENA also studies and develops resources for linguistic varieties that have been spoken within Greece for centuries or by significant populations today but do not belong to the Greek language family, such as Pomak (Slavic language family) and Arvanitika and Gheg (Albanian language family).
At the ATHENA Research Center, specifically at the Institute for Language and Speech Processing (ILSP) and the ARCHIMEDES research unit, we develop AI and Natural Language Processing methods and tools for these linguistic varieties, as follows:
- We collect authentic spoken dialectal data, primarily through fieldwork.
- We develop automatic speech recognition (ASR) models.
- We normalize transcriptions of spoken material while respecting the written tradition and characteristics of each linguistic variety.
- We use existing dialectal texts and transcriptions of spoken data to develop treebanks with detailed morphosyntactic and morphophonological annotation.
- We use the treebanks to train neural models for morphosyntactic analysis of the same or similar linguistic varieties.
The research outputs include spoken corpora, ASR models, morphosyntactic analysis models, treebanks, and annotation guidelines—all available as open-access resources.
Regarding the treebanks, the annotation follows the Universal Dependencies (UD) framework. The treebanks can be retrieved from the current site, which links to the UD repository where the morphosyntactic specifications for each treebank are also located. For each treebank, we provide its name, a link to its UD repository, and the preferred citation format. Specifically for the GUD treebank of Standard Modern Greek, certain accompanying resources are provided: lists of fixed multiword functional expressions and scripts for identifying and discovering multiword expressions with neural models.
At the same time, we use Large Language Models (LLMs) to explore the creation of synthetic data and the comparative study of linguistic varieties, aiming to strengthen their presence in the field of Artificial Intelligence.
The following researchers have contributed to the work described above:
- Antonis Anastasopoulos, Assistant Professor, George Mason University & Archimedes/ATHENA RC
- Stella Markantonatou, Research Director, ILSP/Athena RC & Archimedes/Athena RC
- Angela Ralli, Professor Emerita of Linguistics, University of Patras & Archimedes/ATHENA RC
- Giorgos Paraskevopoulos, Researcher C, ILSP/ATHENA RC
- Chara Tsoukala, Senior Researcher, ILSP/ATHENA RC
- Vivian Stamou, PostDoc Researcher, Archimedes/ATHENA RC
- Stavros Bompolas, PostDoc Researcher, Archimedes/ATHENA RC
- Antonis Dimakis, PhD Student, NKUA & Archimedes/ATHENA RC
- Yannis Kazos, Electrical Engineer, Undergraduate Student, NTUA & Archimedes/ATHENA RC
Available Resources and Models
|
Speech corpora |
ASR models | Treebanks |
Neural morphosyntactic models |
|
| Modern Greek dialects |
Aivaliot |
Aivaliot | ||
| Aperathiot | ||||
| Cappadocian | Cappadocian v1 |
|
||
|
|
East Cretan | Cretan v1 | Cretan | Cretan |
| West Cretan |
|
|||
|
|
Cypriot Greek | Cypriot Greek | ||
| Lesbian | Lesbian v1 | Lesbian | ||
|
|
Messenian | Messenian | ||
| Standard Modern Greek |
|
Standard Modern Greek | ||
|
Non-Greek language varieties spoken in Greece |
Albanian Gheg | |||
| Pomak | Pomak | Pomak |
Contact points
Stella Markantonatou, marks@athenarc.gr
Vivian Stamou, vistamou@athenarc.gr
Σταύρος Μπόμπολας, s.bompolas@athenarc.gr
References
Vasileios Arampatzakis, Vivian Stamou, Stella Markantonatou, and George Pavlidis. 2025. Exploring Active Learning Approaches in Treebank Development. In George Pavlidis and Stella Sylaiou, editors, Transforming Heritage Research in a Transforming World: 5th CAA-GR Conference 2024, Springer Proceedings in Archaeology and Heritage, pages 417–425. Springer Nature Switzerland, Cham.
Stavros Bompolas, Stella Markantonatou, Angela Ralli, and Antonios Anastasopoulos. 2025. Crossing Dialectal Boundaries: Building a Treebank for the Dialect of Lesbos through Knowledge Transfer from Standard Modern Greek. In Gosse Bomma and Çağrı Çöltekin, editors, Proceedings of the Eighth Workshop on Universal Dependencies (UDW, SyntaxFest 2025), pages 39–51, Ljubljana, Slovenia. Association for Computational Linguistics.
Ritván Jusúf Karahóǧa, Panagiotis G. Krimpas, Vivian Stamou, Vasileios Arampatzakis, Dimitrios Karamatskos, Vasileios Sevetlidis, Nikolaos Constantinides, Nikolaos Kokkas, George Pavlidis, and Stella Markantonatou. 2022. Morphologically annotated corpora of Pomak. In Sarah Moeller, Antonios Anastasopoulos, Antti Arppe, Aditi Chaudhary, Atticus Harrigan, Josh Holden, Jordan Lachler, Alexis Palmer, Shruti Rijhwani, and Lane Schwartz, editors, Proceedings of the Fifth Workshop on the Use of Computational Methods in the Study of Endangered Languages, pages 179–186, Dublin, Ireland. Association for Computational Linguistics.
Nikolaos T. Kokkas, Stella Markantonatou, and Vasileios Arampatzakis. 2025. Exploration and Digitization of the Pomak Linguistic Corpus. In George Pavlidis and Stella Sylaiou, editors, Transforming Heritage Research in a Transforming World: 5th CAA-GR Conference 2024, Springer Proceedings in Archaeology and Heritage, pages 407–415. Springer Nature Switzerland, Cham.
Stella Markantonatou, Stavros Bompolas, Chara Tsoukala, Socrates Vakirtzian, Vivian Stamou, Angela Ralli, and Antonios Anastasopoulos. 2024. Dialect-aware Modelling for Modern Greek. Paper presented at the 10th International Conference on Modern Greek Dialects and Linguistic Theory (10-12 October -Bova, Rochudi Nuovo, Galliciano, Italy).
Stella Markantonatou, Vivian Stamou, Stavros Bompolas, Katerina Anastasopoulou, Irianna Linardaki Vasileiadi, Konstantinos Diamantopoulos, Yannis Kazos, and Antonios Anastasopoulos. 2025. VMWE identification with models trained on GUD (a UDv.2 treebank of Standard Modern Greek). In Atul Kr. Ojha, Voula Giouli, Verginica Barbu Mititelu, Mathieu Constant, Gražina Korvel, A. Seza Doğruöz, and Alexandre Rademaker, editors, Proceedings of the 21st Workshop on Multiword Expressions (MWE 2025), pages 14–20, Albuquerque, New Mexico, U.S.A. Association for Computational Linguistics.
Stella Markantonatou, Nicolaos Th. Constantinides, Vivian Stamou, Vasileios Arampatzakis, Panagiotis G. Krimpas, and George Pavlidis. 2023. Methodological issues regarding the semi-automatic UD treebank creation of under-resourced languages: the case of Pomak. In Loïc Grobol and Francis Tyers, editors, Proceedings of the Sixth Workshop on Universal Dependencies (UDW, GURT/SyntaxFest 2023), pages 27–35, Washington, D.C. Association for Computational Linguistics.
Chara Tsoukala, Stavros Bompolas, Antigoni Margariti, Konstantina Panagiotou, Maria Elisavet Plaiti, Nefeli Tzanakaki, Petros Karatsareas, Angela Ralli, Antonios Anastasopoulos, and Stella Markantonatou. 2026. Extending ASR Evaluation Resources for Modern Greek Dialects. In Proceedings of the 13th Workshop on NLP for Similar Languages, Varieties and Dialects, Rabat, Morocco. Association for Computational Linguistics.
Chara Tsoukala, Kosmas Kritsis, Ioannis Douros, Athanasios Katsamanis, Nikolaos Kokkas, Vasileios Arampatzakis, Vasileios Sevetlidis, Stella Markantonatou, and George Pavlidis. 2023. ASR pipeline for low-resourced languages: A case study on Pomak. In Oleg Serikov, Ekaterina Voloshina, Anna Postnikova, Elena Klyachko, Ekaterina Vylomova, Tatiana Shavrina, Eric Le Ferrand, Valentin Malykh, Francis Tyers, Timofey Arkhangelskiy, and Vladislav Mikhailov, editors, Proceedings of the Second Workshop on NLP Applications to Field Linguistics, pages 40–45, Dubrovnik, Croatia. Association for Computational Linguistics.
Socrates Vakirtzian, Vivian Stamou, Yannis Kazos, and Stella Markantonatou. 2025. Dialectal treebanks and their relation with the standard variety: The case of East Cretan and Standard Modern Greek. In Richard Johansson and Sara Stymne, editors, Proceedings of the Joint 25th Nordic Conference on Computational Linguistics and 11th Baltic Conference on Human Language Technologies (NoDaLiDa/Baltic-HLT 2025), pages 776–784, Tallinn, Estonia. University of Tartu Library.
Socrates Vakirtzian, Chara Tsoukala, Stavros Bompolas, Katerina Mouzou, Vivian Stamou, Georgios Paraskevopoulos, Antonios Dimakis, Stella Markantonatou, Angela Ralli, and Antonios Anastasopoulos. 2024. Speech Recognition for Greek Dialects: A Challenging Benchmark. In Interspeech 2024, pages 3974–3978. ISCA.
References in the Media
Διασώζοντας την ντοπιολαλιά με ΑΙ Νewspaper “I Kathimerini”, 8th February 2026